The extraction of information from text is very important for language understanding. There are different kinds of expressions that can be extracted; temporal expressions (timexes) are one kind of these expressions. A temporal expression, as the name says, contains some information about time present in a text. Some examples of timexes are: 1 day, 3 years, in 1 week, etc. These expressions have an explicit value associated, which can be used to perform calculations. However, it is possible to find imprecise expressions, such as a few days, several week, some months, etc., in which a quantified value is not available. These are called imprecise timexes. The question is how to quantify these expressions.
Our research group (C3SL) has developed a solution to extract and normalise this kind of expressions, which is the result of the PhD of Hegler Tissot (a collaboration between UFPR/C3SL and the GATE group at The University of Sheffield)
We have extracted data from several open sources to check the occurrences of precise and imprecise timexes. The imprecise timexes occurrences vary from 7 to 35 percent of the timexes total amount, depending on the kind of text. The ones with higher occurrences were medical texts. The work presented a classification of such expressions: present reference (e.g., now, recently), modified value (e.g., less than a month approximately), imprecise value (e.g., some days, several weeks), range of values (e.g., every 2 months, between some days), partial period (e.g., middle of January) or generic expression (e.g., this time, at the same time).
This work presented a set of normalisation models for each kind of expression; the models are a generalisation of probability distributions in the form of trapezoidal fuzzy membership functions (MSF). The two figures below illustrate the membership functions of imprecise timexes comprising “few”, “some”, “many”, and others, in English and Portuguese.
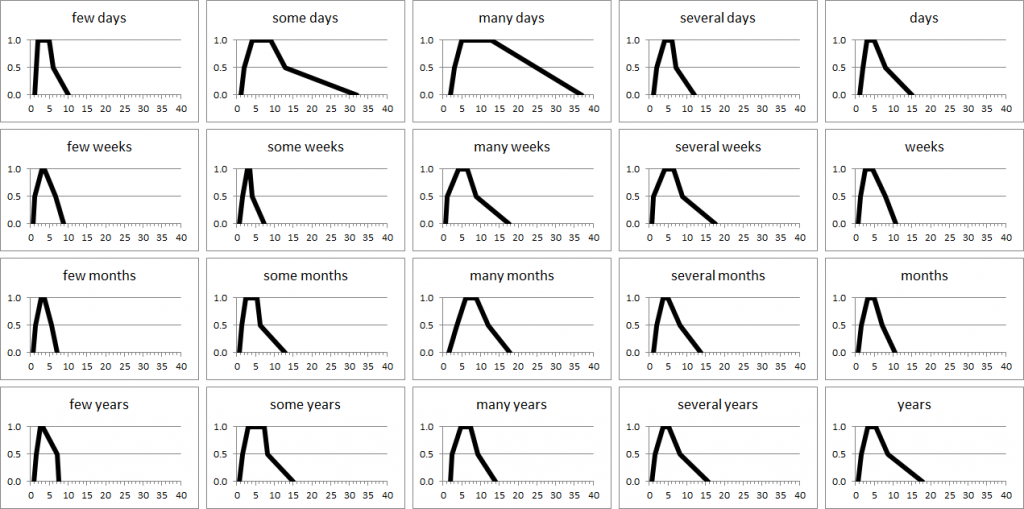
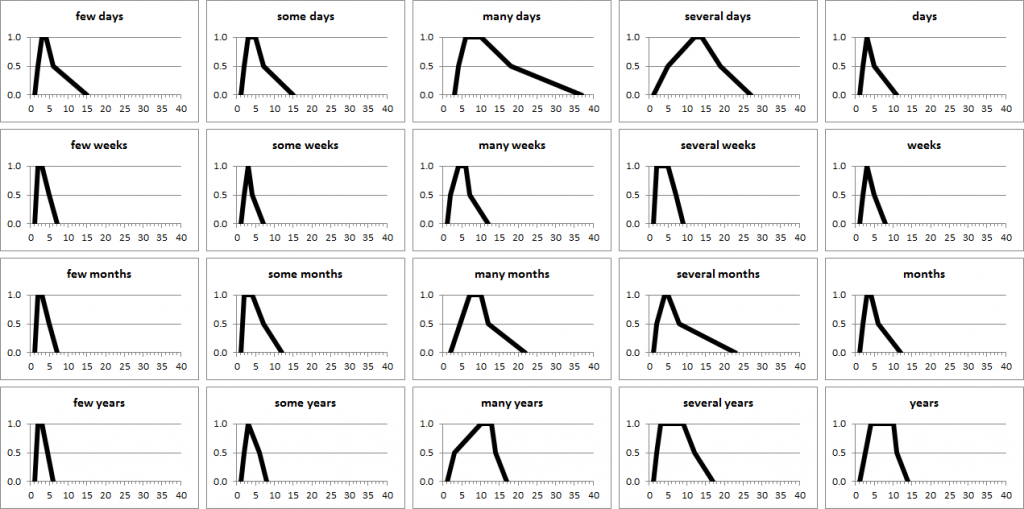
We validated these results using a F1 score, after comparing with a test data set, and also an adapted score which we call F1_3D.
The complete and detailed description of this work have been published this year in the Knowledge And Information Systems journal; it can be downloaded here (Open Access).