Creating drawings of an architecture, of an algorithm, or even of writing a full algorithm in the blackboard or in a piece of paper is an important step when doing R&D in Computer Science. There are some tools that enable online drawings, but I prefer the hand-coded ones!
Recently, I browsed through my photo gallery (in some existing Cloud), because I needed to free some space, and I found some pictures of my office blackboard, which I call “research drawings”. By coincidence, I was recently chatting with a colleague about the great (or awful) ideas we draw in the blackboard, and how some of them yield research subjects, master or Phd works. Some ideas haven’t been published at all, either because they were not good enough, or because we just didn’t have the priority to develop them. If we were to have saved all of our research drawings, we would have a research history, with successful cases (or not). Either way, it always gives us an overview of the work.
The hard part is to remember what they were, or to understand my own letter and what all the boxes mean. Anyway, I decided to post some of them, in chronological order, with some (imprecise) history on how the were made. I do not intend to explain each drawing in detail, but just to comment on them since they were very useful. Some are still top secret, maybe one day I will publish them as well. 🙂
This was not a drawing I made, but it was made by a professor from the department, in a group meeting. The photo was taken around 2012/2013, while we were designing an architecture for querying over multiple data sources. We haven’t published the main idea, but smaller parts, such as the Chameleon tool (main authors: Edson Ramiro and Eduardo Almeida).

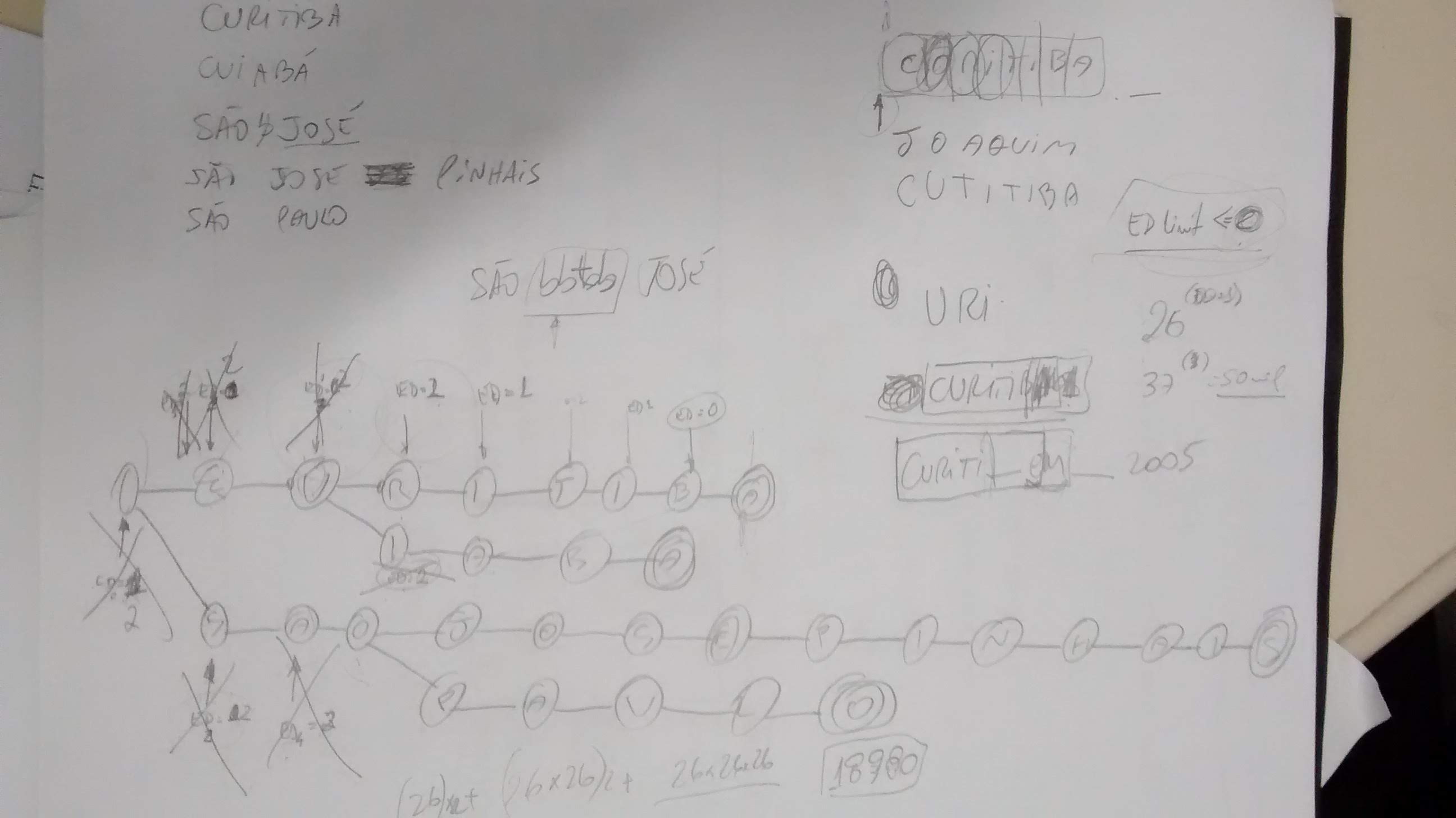
The following one was made in 2014/2015 to understand a specific kind of TRIE tree. I finally understood it, and we integrated it with a phonetic encoding in an Approximate String Matching (ASM) approach (published this year at ADBIS). The main authors were Junior Ferri and Hegler Tissot.
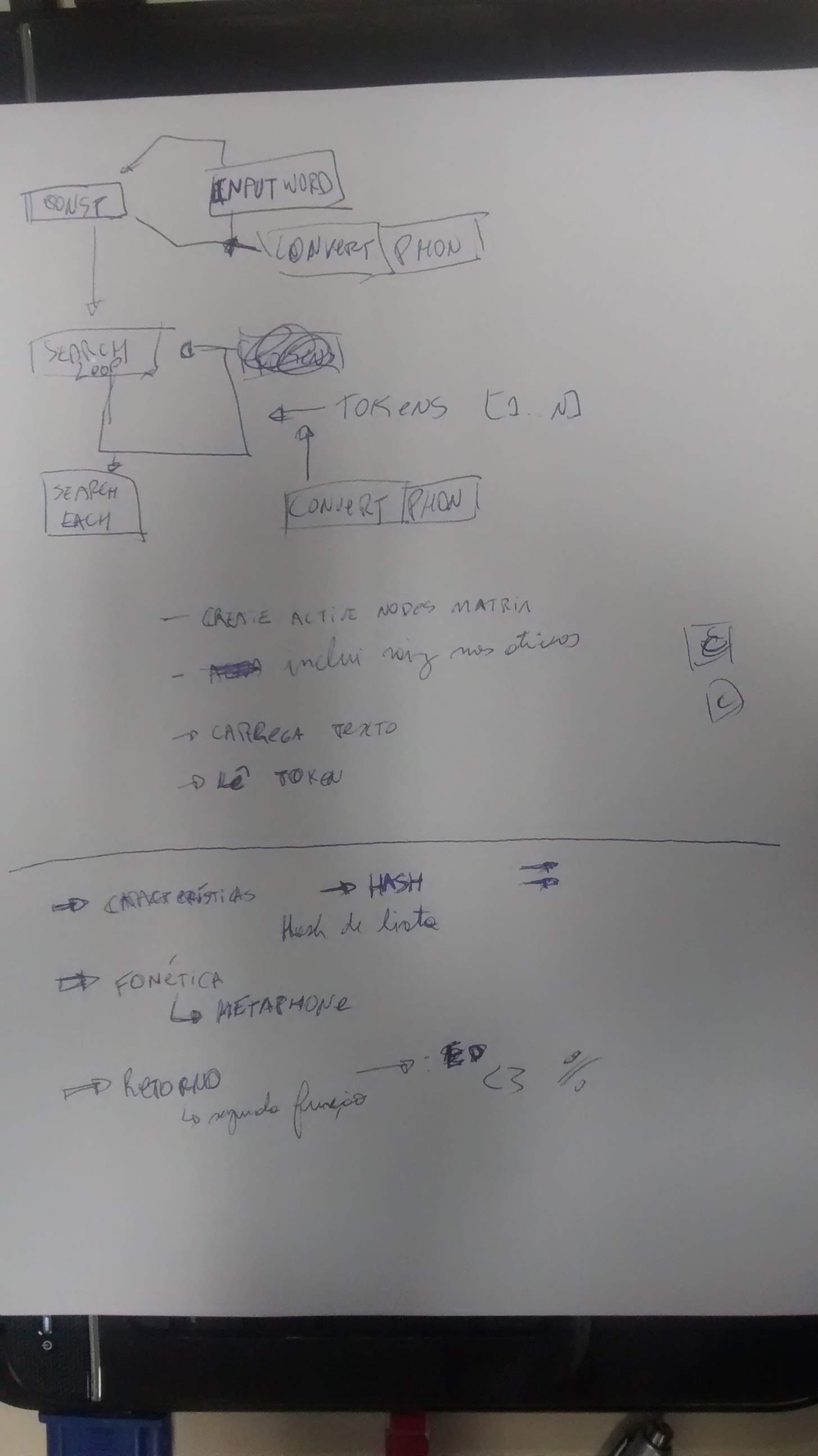
The next one, also made in 2015/2016, is about the same ASM work. It shows the flow of operations to encode a search over a TRIE encoded with phonetic information.
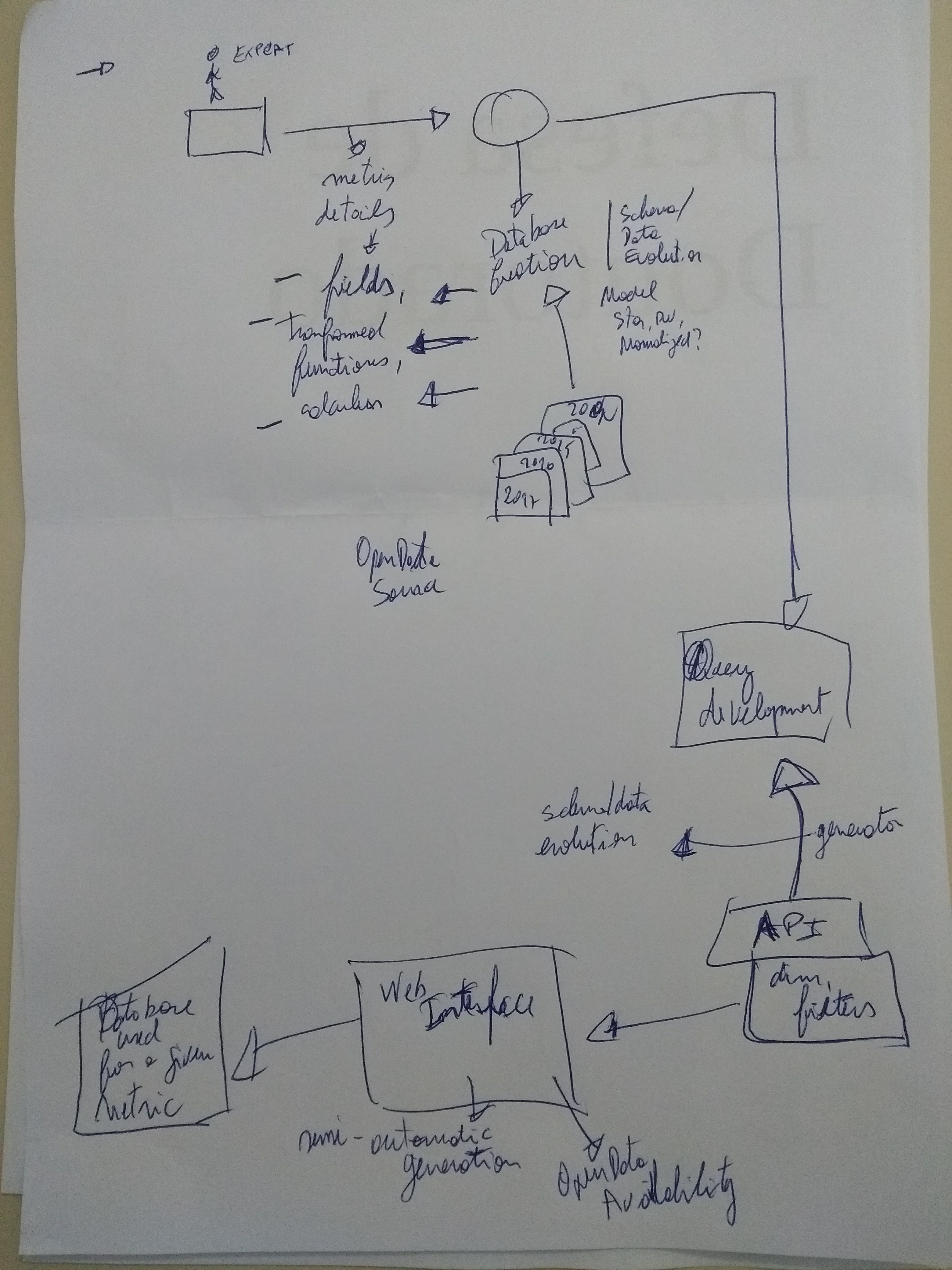
Finally, this one is the general flow of our Open Educational Data Laboratory. It was made in 2018: I remember the year because it is quite recent. In this work, we extract open historical information about education in Brazil (from kindergarten to graduate studies) and we published them in an online platform. There is an article at ICWE this year as well. This one have several things to be developed!