The large availability of Open Data sources encoded in different formats makes the processing and interoperability of these sources difficult. One possible solution (among several others) is to translate the data sources into a common and well-known format, such as JSON documents.
One common source format, prior to its publication, is data encoded using the relational model, maintained by Relational Database Management Systems, informally speaking, because they are used everywhere! We developed a solution to migrate relational databases into JSON documents, called Metamorfose (yes, in Portuguese), implemented on top of Apache Spark.
This work takes as input a relational schema, and it takes as input a DAG (Directed Acyclic Graph) representing the target document model, which does not need necessarily to be JSON. The two figures below have an example of a source schema and 3 possible DAGs, one per target entity.
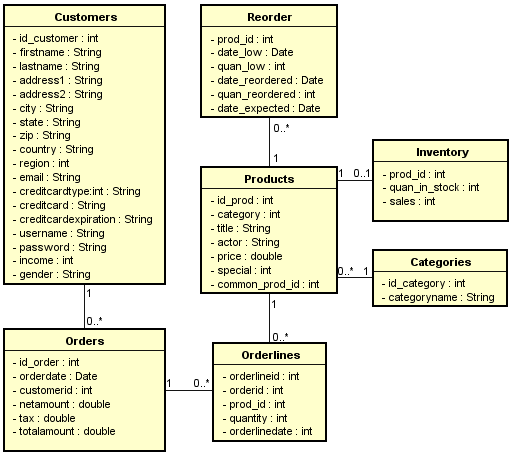
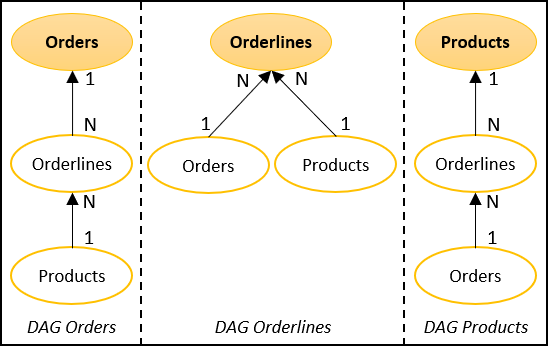
The advantage of creating the DAG above is that is is not necessary to take into account specific implementation details, they are simple, and give a good visual notion of what is going to be the output JSON.
Our work takes this DAG as input and it produces a set of commands that execute the migration. In our specific case, we generated Spark commands, which are combinations of Map and Reduce functions, to execute the migration process. The framework supports as well the definition of UDFs in Javascript, being able to execute quite complex transformations. A sample target is shown in the figure below.
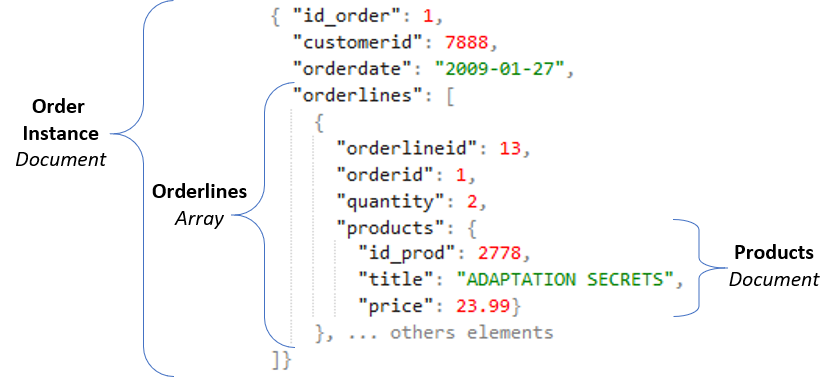
This work has been recently published in the ACM SAC conference 2019. The ones interested in learning the details of the framework can access the paper here and the complete code here. The authors are professor Leticia Peres, myself, and Evandro Kuszera, which is the PhD candidate main responsible for this work!