We have been working on different initiatives to process large amounts of open data and to produce useful information, for instance, the Educational Data Lab or the Web Portal for Educational Resources. One recurrent difficulty is the initial data analysis and transformations, where it is necessary to understand the data before loading it into some specific storage.
In this phase it is often necessary to “play” with the data in several ways, i.e., to apply sets of transformations, to check the results, to re-apply with changes, and so on. It is an interactive process by nature. Existing data extraction tools are not very easy to use (being optimistic),specially complete ETL tools.
In order to have an interactive data transformation tool, our group, and most specifically Evandro Kuszera, developed Metamorfose, an interactive data tranformation tool on top of the Apache Spark framework. The tool has some nice features: 1) a graphical interface is simple, enabling to easily process tabular data; 2) it is possible to process processed data, i.e., to achieve a transformation workflow; 3) the mappings are written in Javascript or SQL, making it ease to start coding. A screenshot of the mappings is shown below. Writting the transformation in Javascript is specially useful for programmers, without the need to install a relational database.
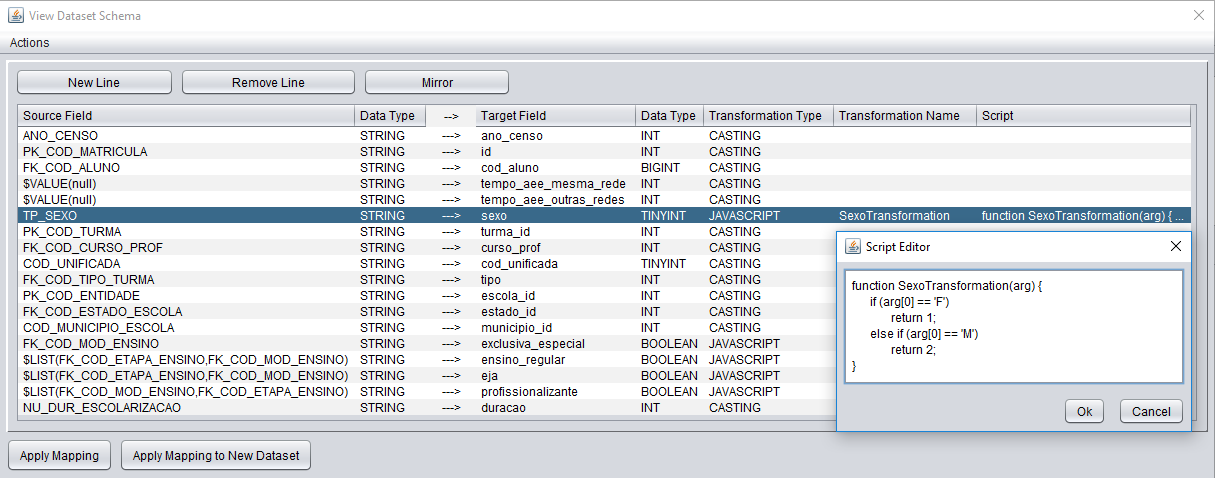
We have applied this tool to process open public data extracted from INEP, with several Gbs, being quite useful to this initial processing. More information about the tool can be find in this nice poster and article (published as a Demo paper at the Brazilian Symposion on Databases – SBBD 2018), as well as its source code here.